
June 25, 2019 Eco DataViz
Keywords: dataviz, R, GIS
Last week I started a Github repository (Link) to practice my data visualization. The data I used last week was Microcystin concentration from Iowa lakes to show trends and evaluate the current year relative to the period of record. Much like #TidyTuesday, as part of the data visualization practice I share the plots and code to spread inspiration and insight into data visualization techniques…the first post went live on Twitter last week with a pretty good reception (couple dozen “likes” and could of “re-tweets”)…couldn’t have been happier!
My Eco #DataViz is pretty basic, its not done in the tidyverse coding style or visualized in ggplot. Everything I do is in base R because that is what I am comfortable doing. The whole goal of Eco #DataViz much like #TidyTuesday is to practice wrangling and visualizing data. In general I follow the guidelines of #TidyTuesday:
This is NOT about criticizing the original article or graph. Real people made the graphs, collected or acquired the data! Focus on the provided dataset, learning, and improving your techniques in R.
This is NOT about criticizing or tearing down your fellow #RStats practitioners! Be supportive and kind to each other! Like other’s posts and help promote the #RStats community!
Share the visualization on Twitter.
Include a copy of the code used to create your visualization. I attempt to comment your code wherever possible to help myself and others understand my process (I know scary)!
Focus on improving your craft, even if you end up with something simple!
Give credit to the original data source whenever possible.
This blog post is the next iteration of Eco #DataViz where I can provide a more in-depth look into the process, share code and data visualizations.
This week I decided to move out of aquatic ecosystem and into something I have always been interested in…climate change science. Recently a version of this image has been making the rounds on twitter sparking concern and interest.
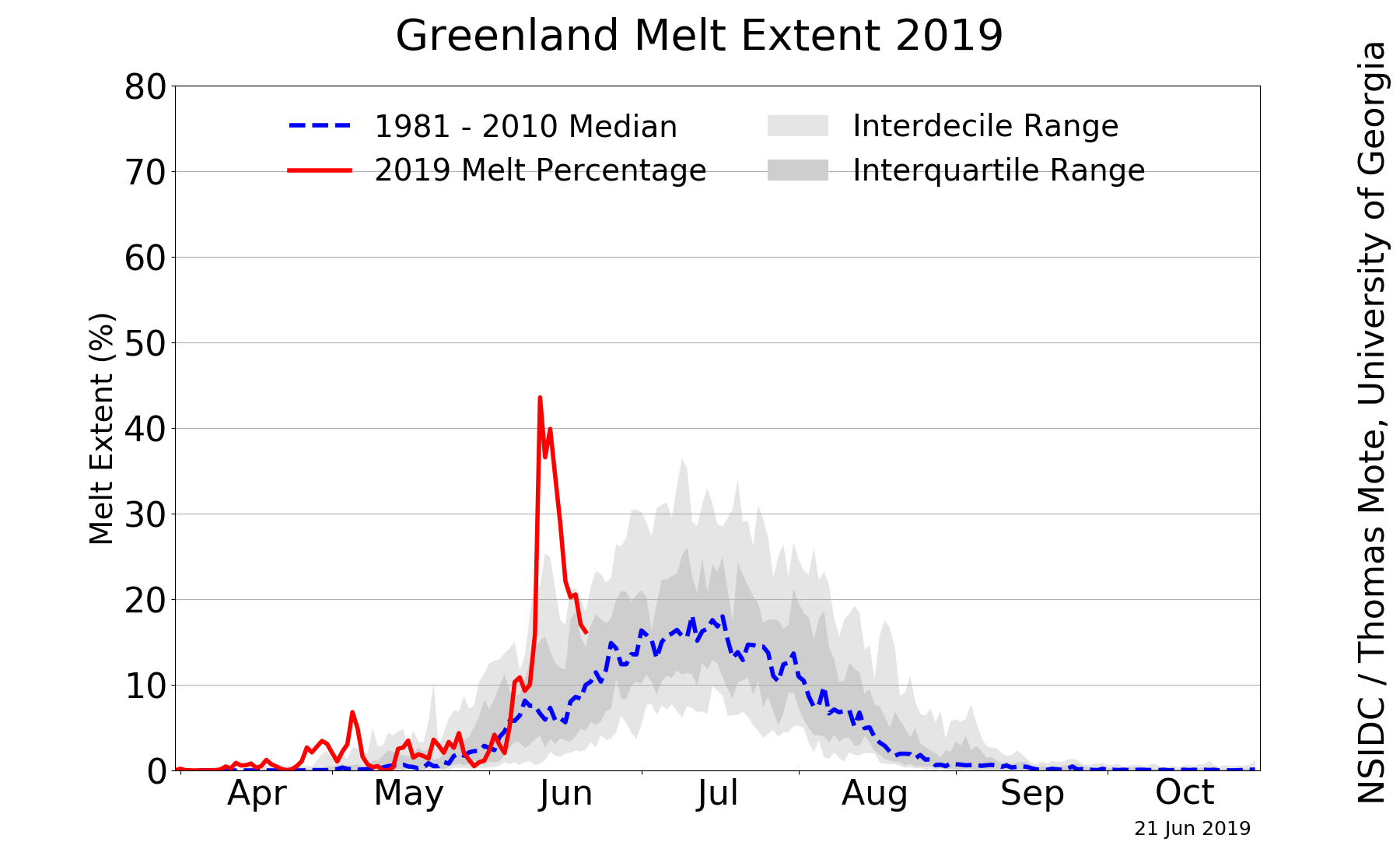
Being the data nerd I am I decided to dig into the data after reading Lisa Charlotte’s blog post on this data and some additional data visualizations of the data. Also an r-script to pull data from the National Snow & Ice Data Center(NSIDC)! A huge thanks to the NSIDC for making this data available!
Before grabbing the data lets load the necessary libraries I used.
The AnalystHelper library is a package I put together of the functions I use on a daily basis…most are helper functions for plotting some actually pull data and others do things. Check out the package here…most likely this will never make it on CRAN but if it helps you out great!!
Alright lets get the data…
years=seq(1979,2019,1)
green.melt=data.frame()
for(i in 1:length(years)){
# pulls the data from the web
d1=fromJSON(file=paste0('https://nsidc.org/api/greenland/melt_area/', years[i]));
#puts in into a temporary file (natively its a list)
tmp=data.frame(Date=as.Date(names(unlist(d1))), MeltArea.sqkm=unlist(d1))
#fixes the row names
row.names(tmp)=1:nrow(tmp)
#combines with the prior year
green.melt=rbind(tmp,green.melt)
}You can write green.melt to a file if needed (i.e. write.csv) or use it in your process. This data represents melt area of the Greenland ice sheet in square kilometers. Granted there are some limitation to this data because it is remotely sensed data but given the period or record some valuable insights into trends and magnitude of change can be determined. If you are interesting about the data, NSIDC has an “About the data” page.
Before really jumping into the data lets work with the date field (screaming is allowed at this point…now that is done let get to it). I use date.fun(), a function in AnalystHelper to help me format dates…I work with lots of time-series data so I made a quick helper function, check out ?date.fun for more info.
green.melt$Date=date.fun(green.melt$Date,tz="GMT");
green.melt$DOY=format(green.melt$Date,"%j");# Day of the Year
green.melt$CY=as.numeric(format(green.melt$Date,"%Y"));# Calendar YearIn the original image, the units are in percent of area…the data we just downloaded is in square kilometers. After some digging I figured out the Greenland ice-sheet is approximately 1,710,000 km2 so lets insert a variable
Now we can convert the melt area in km2 to percent area like in the original image and calculate some statistics.
green.melt$MeltArea.per=(green.melt$MeltArea.sqkm/greenland.ice.area)*100
green.melt.POR.stats=ddply(subset(green.melt,CY%in%seq(1979,2018,1)),"DOY",
summarise,
N.val=N(MeltArea.per),
decile.10=quantile(MeltArea.per,probs=0.1,na.rm=T),
decile.90=quantile(MeltArea.per,probs=0.9,na.rm=T),
Q25=quantile(MeltArea.per,probs=0.25,na.rm=T),
Q75=quantile(MeltArea.per,probs=0.75,na.rm=T),
median=median(MeltArea.per,na.rm=T))
green.melt.ref.stats=ddply(subset(green.melt,CY%in%seq(1981,2010,1)),"DOY",
summarise,
N.val=N(MeltArea.per),
median=median(MeltArea.per,na.rm=T))Goal: Replicate Greenland Daily Melt Plot
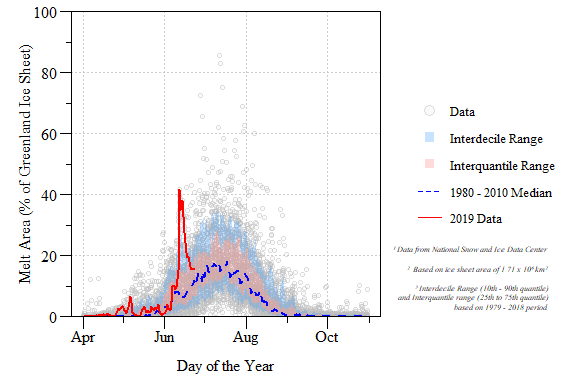
Calendar year 2019 Greenland surface melt extent relative to the 1979 to 2018 period of record.
DONE! and with some added flair.
While digging through the data a couple of questions come to mind…here are two.
Q1 Has the average trend in Greenland melt area increased?
To answer this question we need to calculate annual mean melt area across the period of record. I also included a calculation of \(\pm\) 95% Confidence Interval. I limited the data to just years with a full amount of data and since we are in the middle of the year, 2019 was excluded. N() is a function in AnalystHelper essentially length(which(x!=NA)) to give an actual count of the data…check out ?AnalystHelper::N.
alpha=0.95;
greenland.melt.mean=ddply(subset(green.melt,CY%in%seq(1979,2018,1)),"CY",
summarise,
mean.val=mean(MeltArea.sqkm,na.rm=T),
sd.val=sd(MeltArea.sqkm,na.rm=T),
N.val=N(MeltArea.sqkm))
#Degree of freedom
greenland.melt.mean$Df=greenland.melt.mean$N.val-1;
#Test Statistic
greenland.melt.mean$Tp=with(greenland.melt.mean,abs(qt(1-alpha,Df)));
#Lower CI
greenland.melt.mean$LCI=with(greenland.melt.mean,
mean.val-sd.val*(Tp/sqrt(N.val)));
#Upper CI
greenland.melt.mean$UCI=with(greenland.melt.mean,
mean.val+sd.val*(Tp/sqrt(N.val))); 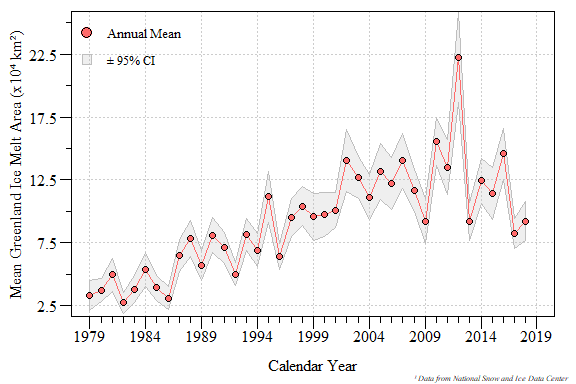
Annual average Greenland melt area with 95% confidence interval for calendar year 1979 to 2018.
Now to see if this trend is significant we can apply a basic Kendall correlation analysis.
##
## Kendall's rank correlation tau
##
## data: mean.val and CY
## T = 632, p-value = 1.074e-09
## alternative hypothesis: true tau is not equal to 0
## sample estimates:
## tau
## 0.6205128I would say the annual mean melt area has significantly increased over the entire period of record!!
Q2 Has the peak melt area increased during the period of record?
Let figure out when the peak melt area has occurred every year. I did this by looping through each year to find the max melt area and extract the date/DOY.
max.melt.CY=data.frame()
for(i in 1:length(seq(1979,2018,1))){
CY.max=max(subset(green.melt,CY==years[i])$MeltArea.sqkm,na.rm=T)
tmp.dat=subset(green.melt,CY==years[i]&MeltArea.sqkm==CY.max)
tmp.dat.final=data.frame(CY=years[i],
DOY.max.melt=as.numeric(min(tmp.dat$DOY,na.rm=T)),
max.melt=CY.max)
max.melt.CY=rbind(tmp.dat.final,max.melt.CY)
}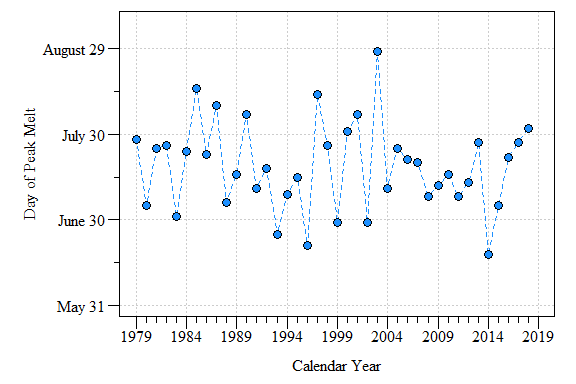
Day of max melt area between calendar year 1979 to 2018.
Lots of variability in the data with some years occurring relatively yearly and others later in the year. More digging is needed to pull this trend out and mechanisms behind it…exciting (and worrisome) frontiers in Arctic and data science.