
Too much outside the box - Outliers and Boxplots
Keywords: boxplots, outlier, data analysis
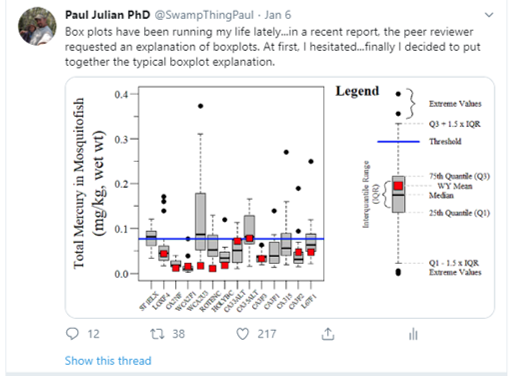
In a recent commentary due out in Marine Biology soon (hopefully) I argue against the use of boxplots as a method of outlier detection. Also seems that boxplots are very popular with people having strong opinons …
Before we get too into the weeds lets present the classical definition of what an outlier is, here I use Gotelli and Ellison (2013) but across statistical literature outliers are generally defined/described similarly.
“…extreme data points that are not characteristic of the distribution they were sampled…” (Gotelli and Ellison 2013).
What would a classic example of this definition look like in “real data” (below is generated data…technically not real data)?
Here is how the data was generated for demonstration purposes
set.seed(123)
# "Data
N.val<-100
x.val<-seq(0,1,length.out=N.val)
m<-5
b<-1
error.val<-1
y.val<-((m*x.val)+b)+rnorm(N.val,0,error.val)
# Outlier
y.val.out<-y.val[95]+2.5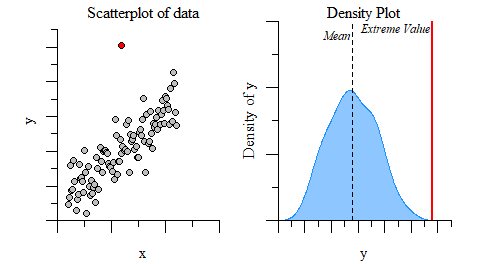
Visual example of an outlier based on the definition above.
Clearly, based on the example above it seems like the red point in the plot to the left looks like it doesn’t really belong. A quick density plot of the data with and without the point (use plot(density(...))) gives you a sense of if the extreme data point is outside of the data distribution. The plot to the right demonstrates the data distribution and mean (dashed) without the extreme value relative to the extreme value (red line).
The next step to really determine if its an outlier would be to conduct an outlier test on your data. Outliers in data can distort the data distribution, affect predictions (if used in a model) and affect the overall accuracy of estimates if they are not detected and handled, especially in bi-variate analysis (such as linear modeling). Most of the information you will see on the internet and in some textbooks is that boxplots are good way to identify outliers. I fully endorse using boxplots as a first looks at the data, just to get a sense of things as they were intended by Tukey (1977). Thats right Dr. John W Tukey was the mastermind behind the boxplot…you may remember him from such statistical analyses as Tukey’s range test/HSD or Tukey lambda distribution.
Overall, boxplots are extremely helpful in quickly visualization of the central tendency and spread of the data. Don’t confuse the central tendency and spread for mean and standard deviation, as these values are not usually displayed in boxplots.
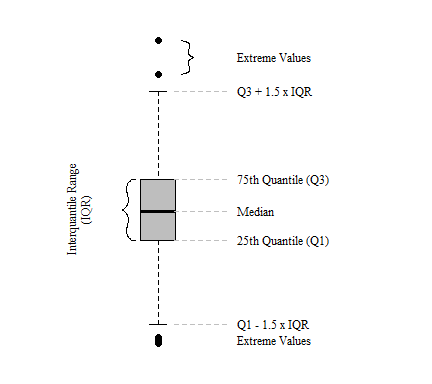
Components of a classic Tukey boxplot.
At its root, boxplots providing no information on the underlying data distribution and provide a somewhat arbitrary detection of extreme values especially for non-normal data distributions (Kampstra 2008; Krzywinski and Altman 2014). Extreme values are identified using a univariate boxplot simply identifies values that fall outside of 1.5 time the inter-quartile range (IQR) of the first or third quartile (Tukey 1977). As discussed above, outliers are extreme values outside the distribution of the data. Since IQR (i.e. median, 25th quantile, 75th quantile, etc.) calculations are distributionless calculations, values outside the IQR therefore are not based on any distribution. Below are four examples of data pulled from different distributions with a mean of zero (\(\mu = 0\)) and standard deviation of one (\(\sigma = 1\)). In these cases, especially for normally and skewed normal distributions, median, 25th quantile and 75th quantile values do not differ greatly, but the number of outliers do differ.
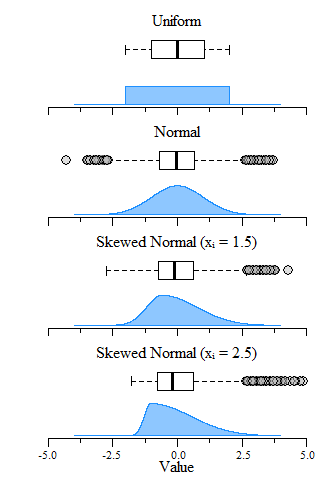
Boxplot and distribution plots of uniform, normal and skewed normal distributions with μ = 0 and σ = 1 (mean and standard deviation) and an N = 10,000.
The boxplot examples above show the span of over 10,000 values pulled from uniform, normal and skewed normal distribtuions. A directly obvious observations is that the uniform distribition does not generate any extreme values while the others generate some depending on the skewness of the distributions. Kampstra (2008) suggests that even for normal distributions the number of extreme values identified will increase concurrently with sample size. This is demonstrated below where as sample size increases, the number of extreme values identified also increases. Furthermore, as sample size increases the IQR estimates narrows which you would expect given the central limit theorem. This sample size dependance ultimately makes individual “outlier” detection problematic.
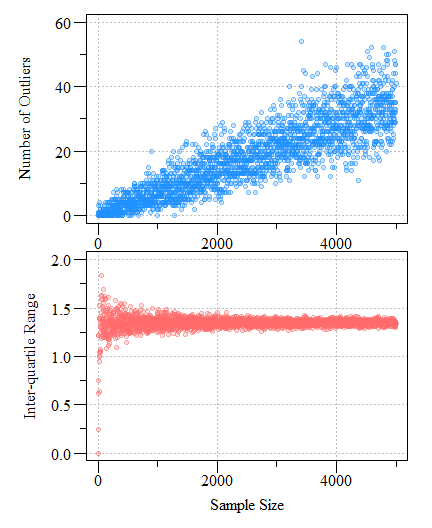
Number of potential outliers detected using a univariate boxplot (top) and inter-quartile range as a function of sample size (bottom) from a normally distributed simulated dataset with a mean of zero and a standard deviation of one (μ = 0; σ = 1).
Bottom line, a boxplot is not a suitable outlier detection test but rather an exploratory data analysis to understand the data. While boxplots do identify extreme values, these extreme values are not truely outliers, they are just values that outside a distribution-less metric on the near extremes of the IQR. Outlier tests such as the Grubbs test, Cochran test or even the Dixon test all can be used to idenify outliers. These tests and more can be found in the outlier R package. Outlier identification and culling is a tricky situtation and requires a strong and rigirous justification and validation that data points identified as an outlier is truely an outlier otherwise you can run afoul of type I and/or type II errors.
References
Gotelli, Nicholas J., and Aaron M. Ellison. 2013. A Primer of Ecological Statistics. Sunderland, MA: Sinauer Associates, Inc.
Kampstra, Peter. 2008. “Beanplot: A Boxplot Alternative for Visual Comparison of Distributions.” Journal of Statistical Software 28 (Code Snippet 1). https://doi.org/10.18637/jss.v028.c01.
Krzywinski, Martin, and Naomi Altman. 2014. “Visualizing Samples with Box Plots.” Nature Methods 11 (2): 119–20. https://doi.org/10.1038/nmeth.2813.
Tukey, John Wilder. 1977. “Exploratory Data Analysis.” In Statistics and Public Policy, edited by Frederick Mosteller, 1st ed. Addison-Wesley Series in Behavioral Science. Quantitative Methods. Addison-Wesley.