Computes the empirical cumulative distribution function (ECDF) for censored data. Estimates parameters of the distribution, including the mean and quantiles.
cfit(
y,
cens,
conf = 0.95,
qtls = c(0.1, 0.25, 0.5, 0.75, 0.9),
q.type = 6,
Cdf = TRUE,
ecdf.col = 1,
km.orig = TRUE,
printstat = TRUE,
Ylab = NULL
)Arguments
- y
Concentrations plus detection limits for indicator formatted data.
- cens
Censoring indicators (logical. 1 or
TRUE= censored, 0 or FALSE = detected) for indicator formatted data.- conf
The confidence coefficient for confidence intervals around the Kaplan-Meier mean and median. Default = 0.95.
- qtls
Probabilities for the quantiles to be estimated. Defaults are (0.10, 0.25, 0.50, 0.75, 0.90). You may add and/or substitute probabilities -- all must be between and not including 0 to 1.
- q.type
an integer between 1 and 9 selecting one of the nine quantile algorithms used only when km.orig = FALSE. See
stats::quantileand Details below for more detail, default when km.orig = FLASE is set to 6.- Cdf
Logical
TRUE/FALSEindicator of whether to plot the empirical cumulative distribution function (cdf).- ecdf.col
Color for the ecdf plotted step function line. Default is black.
- km.orig
If
TRUE(default), Kaplan-Meier results in the realm below detection limits reported as "NA". IfFALSE, information in the detection limits is used and results in the realm of detection limits reported as "< DL", where DL is the appropriate detection limit.- printstat
Logical
TRUE/FALSEoption of whether to print the resulting statistics in the console window, or not. Default isTRUE.- Ylab
Optional input text in quotes to be used as the variable name on the ecdf plot. The default is the name of the
y1input variable.
Value
If printstat=TRUE: Based on the provided conf value, Kaplan-Meier summary statistics (mean,sd,median), lower and upper confidence intervals around the mean and median value, sample size and percent of censored samples are returned. The specified quantile values are also printed and returned.
If Cdf=TRUE: The ecdf of censored data is plotted.
Details
Moment statistics are estimated using the enparCensored function of the EnvStats package. This avoids a small bias in the mean produced by the NADA package's cenfit function, which uses the reverse Kaplan-Meier procedure, converting left-censored to right-censored data prior to computing the ecdf and mean. See Gillespie et al.(2010) for more discussion on the bias of the estimate of the mean.
Quantiles and their two-sided confidence limits are estimated using the quantile function of the survfit command. See ?quantiles or Helsel et al. (2020) for choosing the q.type; default q.type = 4 (Kaplan-Meier; prob = i/n) when km.orig = TRUE. This is standard procedure in the survival analysis discipline and in the survival package of R, and is also used by the cenfit function in the NADA package. While this is 'industry standard' in medical applications it is a poor choice for observed sample (rather than census) data because it means that the largest observation is assigned a probability equal to 1, the 100th percentile. This implies that this value is never expected to be exceeded when more sample data are collected. It also means the largest observation is not plotted on the ecdf in most software because it is "off the chart". For small datasets in particular it is unlikely that the current largest observation is the largest value in the population and so the resulting ecdf quantiles are likely not opotimal. The default q.type = 6 (Weibull; prob = i/(n+1)) when km.orig = FALSE, though that may be changed by the user. the largest observation plots at a probability less than 1 on the ecdf. Differences in results when differing q.types are used will decrease as sample size increases.
All printed values will also be output to an object if saved. Confidence intervals on the quantiles are also output when data include nondetects. Values are character because of the possibility of a <1, but if no < symbol can be converted to numeric using the as.numeric(...) command. For data without censoring cfit will return numeric values. In that case it returns standard arithmetic mean, standard deviation and quantiles instead of K-M versions.
References
Helsel, D.R., 2011. Statistics for Censored Environmental Data using Minitab and R, 2nd ed. John Wiley & Sons, USA, N.J.
Gillespie, B.W., et al., 2010. Estimating Population Distributions When Some Data Are Below a Limit of Detection by Using a Reverse Kaplan-Meier Estimator. Epidemiology 21, 564-570.
Helsel, D.R., Hirsch, R.M., Ryberg, K.R., Archfield, S.A., and Gilroy, E.J., 2020, Statistical Methods in Water Resources: U.S. Geological Survey Techniques and Methods, book 4, chapter A3, 458 p., https://doi.org/10.3133/tm4a3.
Millard, S.P, 2013. EnvStats: An R Package for Environmental Statistics, 2nd ed. Springer Science+Business Media, USA, N.Y. DOI 10.1007/978-1-4614-8456-1© Springer Science+Business Media New York 2013”
Excerpt From: Steven P. Millard. “EnvStats.” Apple Books.
See also
Examples
data(Brumbaugh)
cfit(Brumbaugh$Hg,Brumbaugh$HgCen)
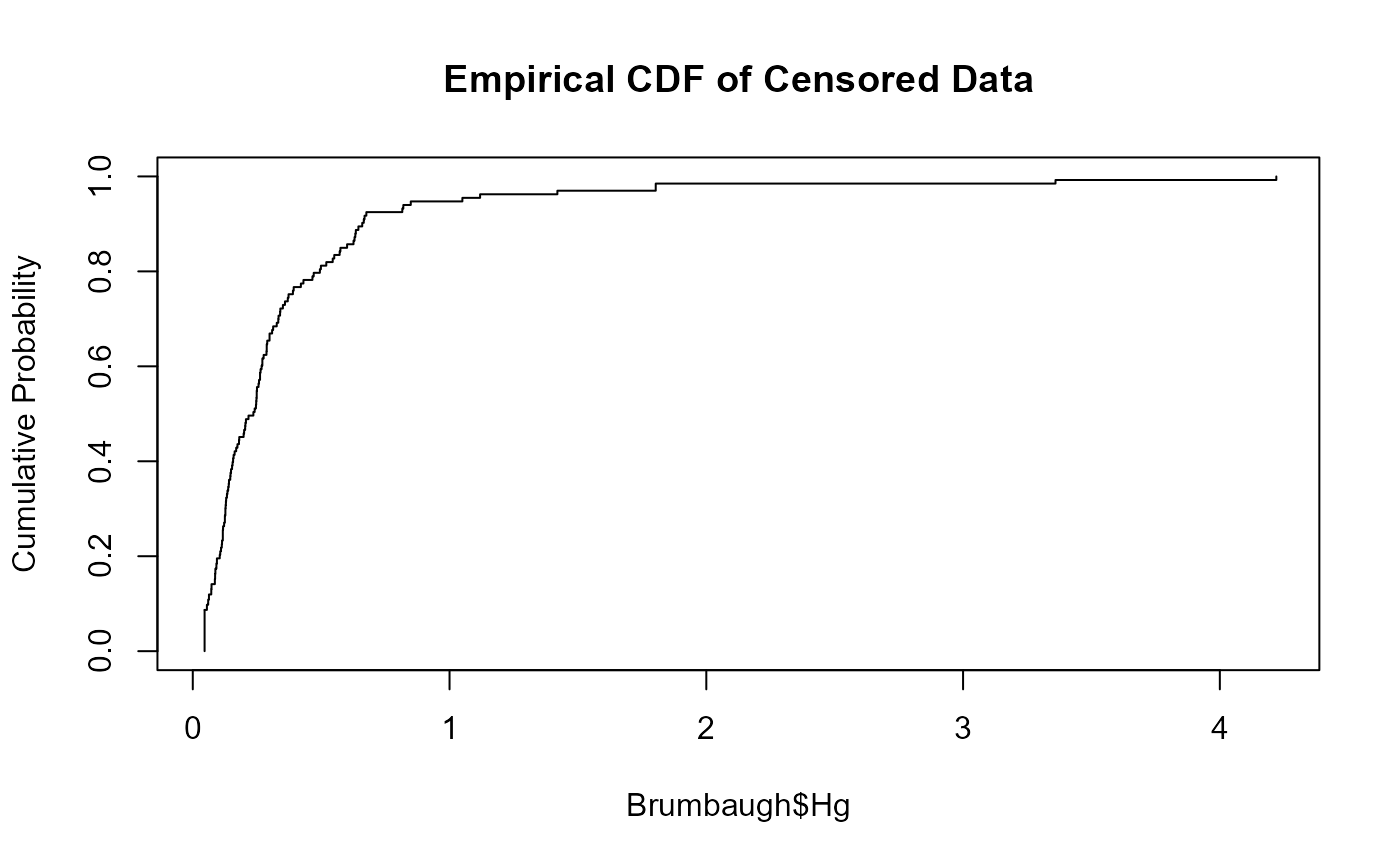 #>
#> Output for Brumbaugh$Hg 95% Confidence Intervals
#> Statistics:
#> N PctND Conf KMmean KMsd LCLmean UCLmean KMmedian LCLmedian UCLmedian
#> 133 11.28 95 0.3565 0.5227 0.2664 0.4465 0.236 0.163 0.262
#>
#> Quantiles: Q10 Q25 Q50 Q75 Q90
#> 0.06 0.117 0.236 0.373 0.66
#>
#>
#> Output for Brumbaugh$Hg 95% Confidence Intervals
#> Statistics:
#> N PctND Conf KMmean KMsd LCLmean UCLmean KMmedian LCLmedian UCLmedian
#> 133 11.28 95 0.3565 0.5227 0.2664 0.4465 0.236 0.163 0.262
#>
#> Quantiles: Q10 Q25 Q50 Q75 Q90
#> 0.06 0.117 0.236 0.373 0.66
#>